HuggingFace course
huggingface course学习
目录
Unit 1. Introduction to Agents
What is an Agent?
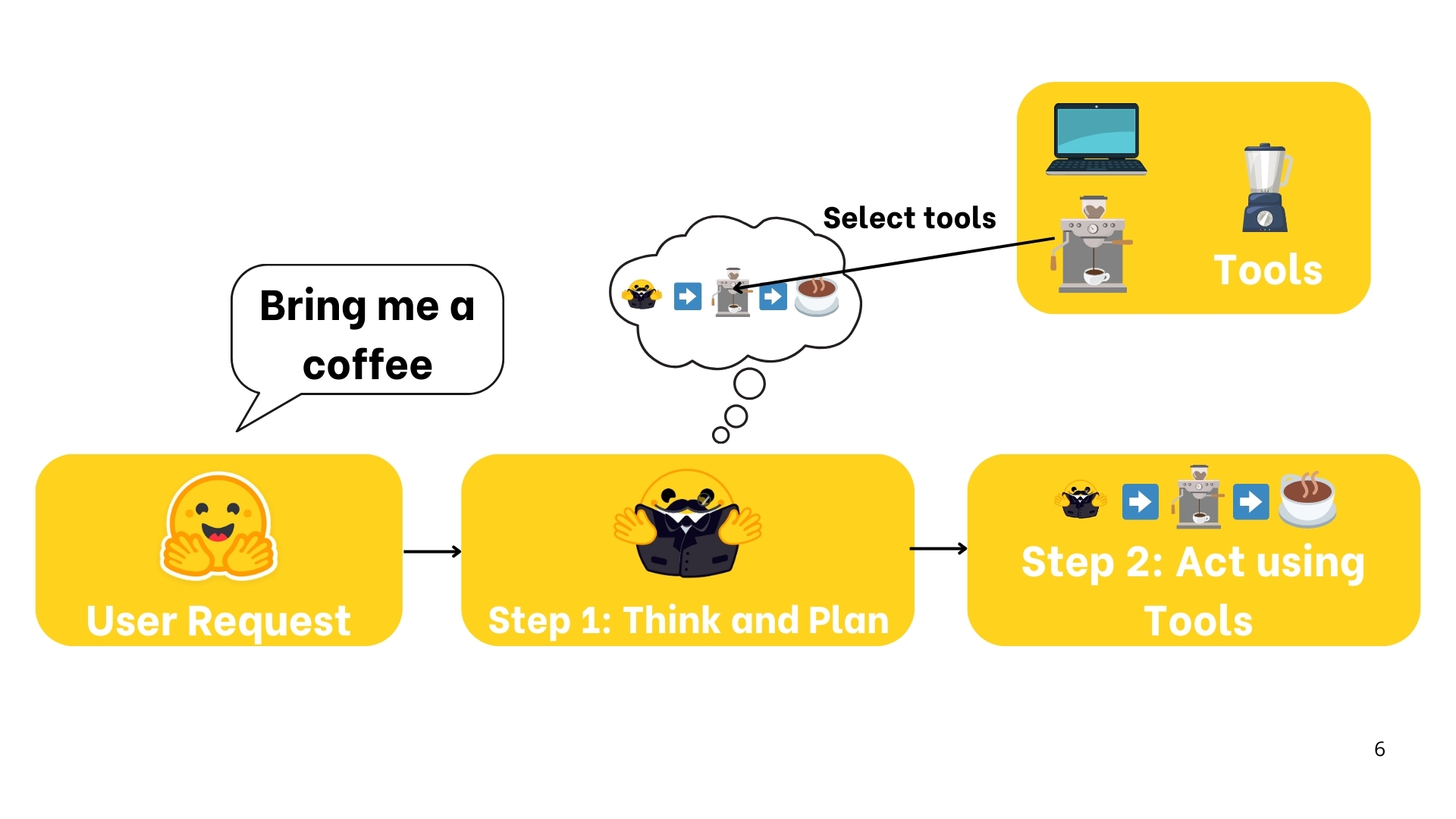
现在有一个人叫flyyy的人,他是agent。想象一下她的女朋友对他说:“flyyy,我想要喝一杯咖啡。”
此时flyyy接收到了指令,因为flyyy可以理解人话(自然语言),所以可以很快的做出相应,把咖啡递给他的女朋友。
在flyyy完成这个动作之前,他需要推理和规划,并且弄清楚自己需要做的步骤和使用到的工具
- 去厨房
- 使用咖啡机
- 冲咖啡
- 把咖啡递给女朋友
下面是流程图,首先flyyy接收到了指令

接着flyyy 尝试理解,并且做出推理和计划

接着是执行

最后女朋友拿到了咖啡

概括一下,用了原文,觉得写的很好
agent: an AI model capable of reasoning, planning, and interacting with its environment.
agent具有与其所处环境交互的能力
An Agent is a system that leverages an AI model to interact with its environment in order to achieve a user-defined objective. It combines reasoning, planning, and the execution of actions (often via external tools) to fulfill tasks.
我们可以将agnet看作两个部分
1.The Brain (AI Model)
AI模型负责推理和规划,并且根据实际的情况来决定采取什么样的措施
2.The Body(Capabilities and Tools)
这部分代表了agent所具备的能力,也就是他能做什么
agent可以做的事情(action)的范围,取决于改agent配备了什么样的工具。比如说,人没有翅膀,所以人不可以飞,但是人可以“唱”、“跳”、“rap”和“打篮球”
不同的智能体具备的能力不一样,所以下面有一个智能体的能力分级
| 智能体等级 | 描述 | 常见称谓 | 示例模式 |
|---|---|---|---|
| ☆☆☆ | 智能体输出不影响程序流程 | 简单处理器 | `processllmoutput(llmresponse)` |
| ★☆☆ | 智能体输出决定基本控制流 | 路由 | `if llmdecision(): patha() else: pathb()` |
| ★★☆ | 智能体输出决定函数调用 | 函数调用者 | `runfunction(llmchosentool, llmchosenargs)` |
| ★★★ | 智能体输出控制迭代及程序延续 | 多步智能体 | `while llmshouldcontinue(): executenextstep()` |
| ★★★ | 一个智能体流程可启动另一个智能体流程 | 多智能体系统 | `if llmtrigger(): executeagent()` |
不同的模型可以做的事情不一样。比如说LLM(Large Language Model),会将文本作为输入,同样的文本作为输出;VLM,会讲图片作为输出……
An Agent can perform any task we implement viaTools to complete Actions.
例如,如果我编写一个Agent作为我计算机上的个人助理(类似 Siri),当我让它 “给我的经理发一封邮件,请求推迟今天的会议” 时,我可以给它一些发送邮件的代码。这将成为代理在需要发送邮件时可以使用的新工具。我们可以用 Python 来编写这个工具:
1 | |
对于LLM来说,会产生这样的调用
1 | |
To summarize, an Agent is a system that uses an AI Model (typically an LLM) as its core reasoning engine, to:
- Understand natural language: Interpret and respond to human instructions in a meaningful way.
- Reason and plan: Analyze information, make decisions, and devise strategies to solve problems.
- Interact with its environment: Gather information, take actions, and observe the results of those actions.
What are LLMs?
What is a Large Language Model?
大型语言模型(LLM)是一种擅长理解和生成人类语言的人工智能模型。它们通过海量文本数据进行训练,从而学习语言中的模式、结构,甚至是细微差别。这类模型通常包含数以百万计的参数。
下面是当今绝大部分Transformer的架构,源自18年google的论文《attention is all your need》
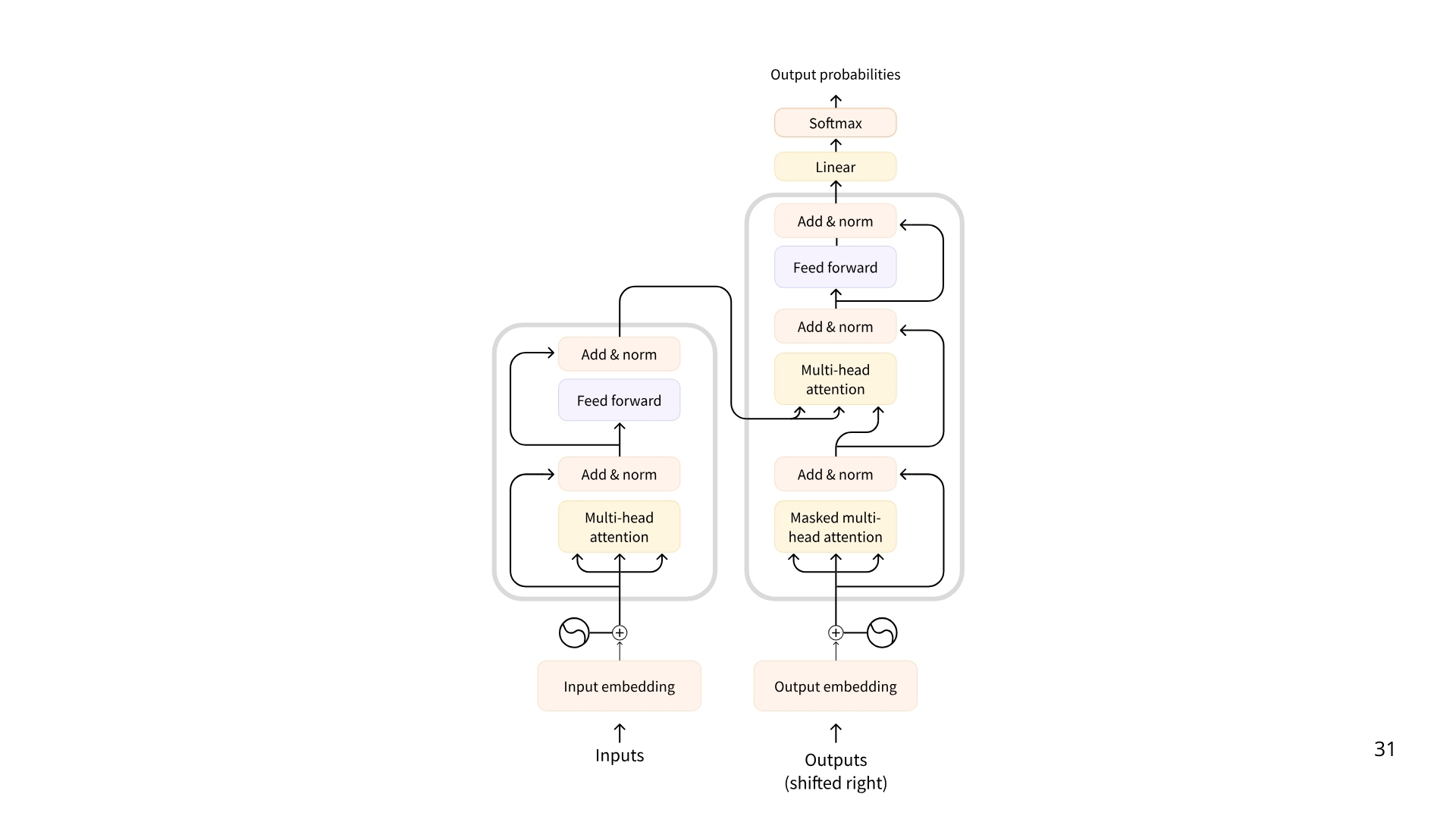
下面是三种transformers
1. 编码器(Encoders)
基于编码器的 Transformer 将文本(或其他数据)作为输入,并输出该文本的稠密表示(或嵌入)。
- 示例:谷歌的 BERT
- 应用场景:文本分类、语义搜索、命名实体识别
- 典型规模:数百万参数
2.解码器(Decoders)
基于解码器的 Transformer 专注于生成新标记以完成序列,每次生成一个标记。
- 示例:Meta 的 Llama
- 应用场景:文本生成、聊天机器人、代码生成
- 典型规模:数十亿参数(此处采用美国计数法,即109)
3.序列到序列模型(Seq2Seq,Encoder–Decoder)
序列到序列 Transformer 结合了编码器和解码器。编码器首先将输入序列处理为上下文表示,然后解码器生成输出序列。
- 示例:T5、BART
- 应用场景:机器翻译、文本摘要、句子改写
- 典型规模:数百万参数
下面就是一些以decoder为基础的模型
| Model | Provider |
|---|---|
| Deepseek-R1 | DeepSeek |
| GPT4 | OpenAI |
| Llama 3 | Meta (Facebook AI Research) |
| SmolLM2 | Hugging Face |
| Gemma | |
| Mistral | Mistral |
大型语言模型(LLM)的基本原理简单却高效:其目标是在给定先前标记序列的情况下,预测下一个标记。“标记”(token)是大型语言模型处理信息的基本单元。你可以将 “标记” 理解为类似 “单词” 的概念,但出于效率考量,大型语言模型并不使用完整的单词。
例如,英语中估计有 60 万个单词,而一个大型语言模型可能仅包含约 3.2 万个标记(如 Llama 2 即是如此)。标记化处理通常基于可组合的子词单元。
举例来说,“interest” 和 “ing” 这两个token可以组合成 “interesting”,或者通过附加 “ed” 形成 “interested”。
每个大型语言模型(LLM)都有一些特定于模型的特殊标记。模型使用这些标记来开启和关闭其生成内容的结构化组件,例如指示序列、消息或响应的开始或结束。此外,我们传递给模型的输入提示也会通过特殊标记进行结构化处理,其中最重要的是序列结束标记(EOS)。
不同模型提供商的特殊标记形式差异很大。
下表展示了特殊标记的多样性。
| Model | Provider | EOS Token | Functionality |
|---|---|---|---|
| GPT4 | OpenAI | `<|endoftext|>` | End of message text |
| Llama 3 | Meta (Facebook AI Research) | `<|eot_id|>` | End of sequence |
| Deepseek-R1 | DeepSeek | `<|end_of_sentence|>` | End of message text |
| SmolLM2 | Hugging Face | `<|im_end|>` | End of instruction or message |
| Gemma | `<end_of_turn>` | End of conversation turn |
Understanding next token prediction
这里描述的LLM如何预测下一个token的策略。其实就是一个终止条件为遇到EOS的循环,每一次的输入会对应一个输出,输出会作为下一次预测的输入,依次重复,直到遇到EOS
换句话说,大型语言模型(LLM)会一直解码文本,直到遇到序列结束标记(EOS)。但在单个解码循环中会发生什么呢?
尽管对于学习智能体(Agent)的用途而言,完整的过程可能相当技术化,但以下是一个简要概述:
- 一旦输入文本被tokenized,模型会计算该序列的表示,这种表示捕获了输入序列中每个标记的含义和位置信息。
- 这种表示会被输入到模型中,模型随后输出分数,对其词汇表中每个标记作为序列中下一个标记的可能性进行排序。
基于这些分数,最简单的方法就是选择分数最高的(出现可能性最大的)
但还有更高级的解码策略。例如,波束搜索(beam search)会探索多个候选序列,以找到总得分最高的序列 —— 即使某些单个标记的得分较低。
第二个方法是看一个语句的总体,比如说我这里采取以下的约束

一共是五个步骤,每一次输入都会有对应的四种可能性,然后每一种可能性会产生三个可能的token,依此这样,最后将所有的到的结果进行排序,选择可能性最大的
其实上面说了一个总体的处理方法,但是需要设想一种情况
比如说我有一个输入,The captial of China is ???显然想要推测出后面的token,我们需要重点关注captial和China,而不是The of 和 is。用户输入内容其实就是prompt,因此精心设计的prompt会让模型跟容易地输出我们想要的内容
How are LLMs trained?
大型语言模型(LLMs)通过海量文本数据集进行训练,在训练过程中,它们基于自监督(self-supervised)学习或掩码语言(masked language )建模目标,学习预测序列中的下一个词。
通过这种无监督学习(unsupervised learning),模型能够掌握语言结构和文本中的潜在模式,从而具备对未见过的数据进行泛化的能力。
在完成初始预训练后,大型语言模型可以通过有监督学习目标进行微调(fine-tuned),以执行特定任务。例如,部分模型会针对对话结构或工具使用场景进行训练,而另一些模型则专注于分类任务或代码生成。